Guided Policy Search¶
This code is a reimplementation of the guided policy search algorithm and LQG-based trajectory optimization, meant to help others understand, reuse, and build upon existing work. It includes a complete robot controller and sensor interface for the PR2 robot via ROS, and an interface for simulated agents in Box2D and Mujoco. Source code is available on GitHub.
While the core functionality is fully implemented and tested, the codebase is a work in progress. See the FAQ for information on planned future additions to the code.
Relevant work¶
Relevant papers which have used guided policy search include:
- Sergey Levine*, Chelsea Finn*, Trevor Darrell, Pieter Abbeel. End-to-End Training of Deep Visuomotor Policies. 2015. arxiv 1504.00702. [pdf]
- Marvin Zhang, Zoe McCarthy, Chelsea Finn, Sergey Levine, Pieter Abbeel. Learning Deep Neural Network Policies with Continuous Memory States. ICRA 2016. [pdf]
- Chelsea Finn, Xin Yu Tan, Yan Duan, Trevor Darrell, Sergey Levine, Pieter Abbeel. Deep Spatial Autoencoders for Visuomotor Learning. ICRA 2016. [pdf]
- Sergey Levine, Nolan Wagener, Pieter Abbeel. Learning Contact-Rich Manipulation Skills with Guided Policy Search. ICRA 2015. [pdf]
- Sergey Levine, Pieter Abbeel. Learning Neural Network Policies with Guided Policy Search under Unknown Dynamics. NIPS 2014. [pdf]
If the codebase is helpful for your research, please cite any relevant paper(s) above and the following:
- Chelsea Finn, Marvin Zhang, Justin Fu, Xin Yu Tan, Zoe McCarthy, Emily Scharff, Sergey Levine. Guided Policy Search Code Implementation. 2016. Software available from rll.berkeley.edu/gps.
For bibtex, see this page.
Installation¶
Dependencies¶
The following are required
- python 2.7, numpy (v1.7.0+), matplotlib (v1.5.0+), scipy (v0.11.0+)
- boost, including boost-python
- protobuf (apt-get packages libprotobuf-dev and protobuf-compiler)
One or more of the following agent interfaces is required. Set up instructions for each are below.
One of the following neural network libraries is required for the full guided policy search algorithm
- Caffe (master branch as of 11/2015, with pycaffe compiled, python layer enabled, PYTHONPATH configured)
- TensorFlow (coming soon)
Setup¶
Follow the following steps to get set up:
Install necessary dependencies above.
Clone the repo:
git clone https://github.com/cbfinn/gps.git
Compile protobuffer:
cd gps ./compile_proto.sh
Set up one or more agents below.
Box2D Setup (optional)
Here are the instructions for setting up Pybox2D.
Install Swig and Pygame:
sudo apt-get install build-essential python-dev swig python-pygame subversion
Check out the Pybox2d code via SVN
svn checkout http://pybox2d.googlecode.com/svn/trunk/ pybox2d
Build and install the library:
python setup.py build sudo python setup.py install
Mujoco Setup (optional)
In addition to the dependencies listed above, OpenSceneGraph(v3.0.1+) is also needed.
Install Mujoco (v1.22+) and place the downloaded
mjprodirectory intogps/src/3rdparty. Mujoco is a high-quality physics engine and requires requires a license. Obtain a key, which should be namedmjkey.txt, and place the key into themjprodirectory.Build
gps/src/3rdpartyby running:cd gps/build cmake ../src/3rdparty make -j
Set up paths by adding the following to your
~/.bashrcfile:export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:gps/build/lib export PYTHONPATH=$PYTHONPATH:gps/build/lib
Don’t forget to run
source ~/.bashrcafterward.
ROS Setup (optional)
Install ROS, including the standard PR2 packages
Set up paths by adding the following to your
~/.bashrcfile:export ROS_PACKAGE_PATH=$ROS_PACKAGE_PATH:/path/to/gps:/path/to/gps/src/gps_agent_pkg
Don’t forget to run
source ~/.bashrcafterward.Compilation:
cd src/gps_agent_pkg/ cmake . make -j


ROS Setup with Caffe (optional)
This is required if you intend to run neural network policies with the ROS agent.
Run step 1 and 2 of the above section.
Checkout and build caffe, including running
make -j && make distributewithin caffe.Compilation:
cd src/gps_agent_pkg/ cmake . -DUSE_CAFFE=1 -DCAFFE_INCLUDE_PATH=/path/to/caffe/distribute/include -DCAFFE_LIBRARY_PATH=/path/to/caffe/build/lib make -j
To compile with GPU, also include the option
-DUSE_CAFFE_GPU=1.
Examples¶
Box2D example¶
There are two examples of running trajectory optimizaiton using a simple 2D agent in Box2D. Before proceeding, be sure to set up Box2D.
Each example starts from a random controller and learns through experience to minimize cost.
The first is a point mass learning to move to goal position.


To try it out, run the following from the gps directory:
python python/gps/gps_main.py box2d_pointmass_example
The progress of the algorithm is displayed on the GUI. The point mass should start reaching the visualized goal by around the 4th iteration.
The second example is a 2-link arm learning to move to goal state.
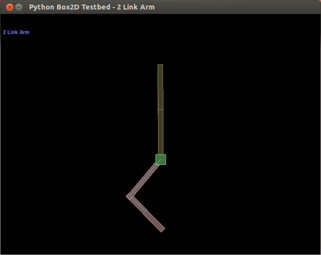
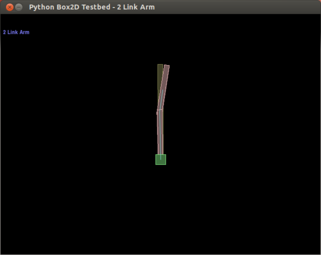
To try it out, run this:
python python/gps/gps_main.py box2d_arm_example
The arm should start reaching the visualized goal after around 6 iterations.
All settings for these examples are located in experiments/box2d_[name]_example/hyperparams.py,
which can be modified to input different target positions and change various hyperparameters of the algorihtm.
Mujoco example¶
To run the mujoco example, be sure to first set up Mujoco.
The first example is using trajectory optimizing for peg insertion. To try it, run the following from the gps directory:
python python/gps/gps_main.py mjc_example
Here the robot starts with a random initial controller and learns to insert the peg into the hole. The progress of the algorithm is displayed on the GUI.


Now let’s learn to generalize to different positions of the hole. For this, run the guided policy search algorithm:
python python/gps/gps_main.py mjc_badmm_example
The robot learns a neural network policy for inserting the peg under varying initial conditions.
To tinker with the hyperparameters and input, take a look at experiments/mjc_badmm_example/hyperparams.py.
PR2 example¶
To run the code on a real or simulated PR2, be sure to first follow the instructions above for ROS setup.
1. Start the controller¶
Real-world PR2
On the PR2 computer, run:
roslaunch gps_agent_pkg pr2_real.launch
This will stop the default arm controllers and spawn the GPSPR2Plugin.
Simulated PR2
Note: If you are running ROS hydro or later, open the launch file pr2_gazebo_no_controller.launch and change the include line as specified.
Launch gazebo and the GPSPR2Plugin:
roslaunch gps_agent_pkg pr2_gazebo.launch
2. Run the code¶
Now you’re ready to run the examples via gps_main. This can be done on any machine as long as the ROS environment variables are set appropriately.
The first example starts from a random initial controller and learns to move the gripper to a specified location.
Run the following from the gps directory:
python python/gps/gps_main.py pr2_example
The PR2 should reach the position shown on the right below, and reach a cost of around -600 before the end of 10 iterations.
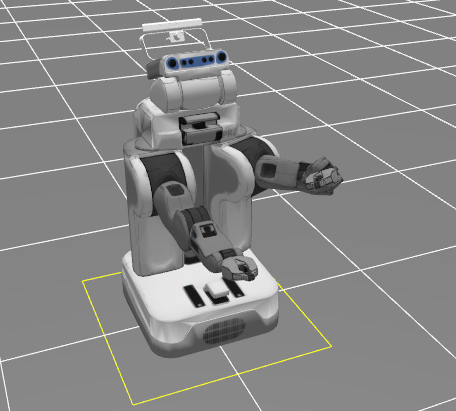
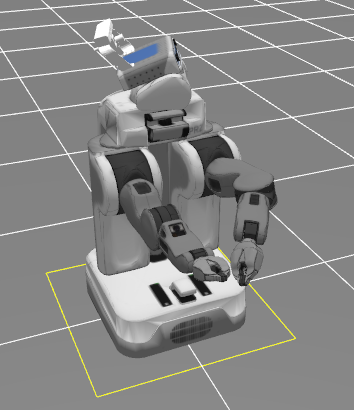
The second example trains a neural network policy to reach a goal pose from different starting positions, using guided policy search:
python python/gps/gps_main.py pr2_badmm_example
To learn how to make your own experiment and/or set your own initial and target positions, see the next section
Running a new experiment¶
Set up a new experiment directory by running:
python python/gps/gps_main.py my_experiment -n
This will create a new directory called my_experiment/ in the experiments directory, with a blank hyperparams.py file.
Fill in a hyperparams.py file in your experiment. See pr2_example and mjc_example for examples.
If you wish to set the initial and/or target positions for the pr2 robot agent, run target setup:
python python/gps/gps_main.py my_experiment -t
See the GUI documentation for details on using the GUI.
Finally, run your experiment
python python/gps/gps_main.py my_experiment
All of the output logs and data will be routed to your experiment directory. For more details, see intended usage.
Documentation¶
In addition to the inline docstrings and comments, see the following pages for more detailed documentation:
Learning with your own robot¶
The code was written to be modular, to make it easy to hook up your own robot. To do so, either use one of the existing agent interfaces (e.g. AgentROS), or write your own.
Reporting bugs and getting help¶
You can post questions on gps-help. If you want to contribute, please post on gps-dev. When your contribution is ready, make a pull request on GitHub.
Licensing¶
 This codebase is released under the CC BY-NC-SA license.
This codebase is released under the CC BY-NC-SA license.